
Tag Archives: information design
Visualizing the National Popular Vote plan
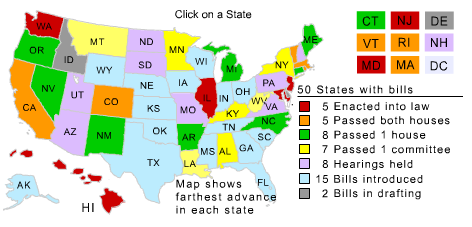
This graphic visualizes the progress of the National Popular Vote plan (more about the politics of this plan in Hacking the Constitution).
The existing visualization on National Popular Vote’s website was flawed enough to inspire this attempt at fixing it. They use a national map with states colored according to the plan’s progress. Using geographical visualization conflicts with the plan’s intention to make the states as entities less influential, and with the plan’s success depending on the number of electoral votes, not the geographical size or population of the states1. And even though the steps in passing the plan suggest a spectrum, the colors are seemingly random.
{kind=link}
Plus NPV is a good cause that deserves more attention. And as a vocal Flash critic, I should put my money where my mouth is and implement a cross-browser, scalable, interactive, vector graphic to show that it can be done without Flash.
Visualizing complex data well is challenging, and this is no exception. The plan will likely be adopted slowly over many years, so the graphic must be designed to expand. The technology must also be future-proof; I don’t want to have to re-implement the graphic, convert it to a different format, or get access to future versions of software, or the operating systems that software must run on, just to keep supporting it. This pretty much rules out Flash and Sliverlight.
These constraints make SVG2 and JavaScript a good choice. SVG support is still nascent in Gecko and WebKit3 (and even Opera supports it), but the standard is pretty usable and I expect it to gain more adoption over time. All of the rendering code is in JavaScript. I’d put money on JavaScript interpreters remaining readily available ten years from now. I unfortunately have no ability (or desire, for that matter) to test this in IE with Adobe’s SVG plugin; if you try it, email me the results.
{kind=link}
There are many different entities involved in the process: fifty states, each with two legislative bodies and a governor, and a total of 538 electoral votes; and many different events: passing the first body of a legislature, passing the second, bills passing the same body subsequent times, being signed into law, being vetoed, vetoes being overridden, and (hopefully never) laws being repealed.
The data comes from disparate sources; most comes from NPV’s website, but I had to search for the vetoes. The data is not just linear; it overlaps and interacts. A veto affects two of the charts but not the third, and a repeal would affect all three. The three charts have an order; a bill cannot pass both houses before it passes one, and cannot be signed into law before it passes both.
To include all this data, a visualization would either have to be interactive or poster-sized. This one is interactive; you can mouse over vertexes in the charts and get more information about the events they represent. You can quickly and easily find out:
- The exact progress of NPV at any time since its introduction.
- Who, what and where for any NPV-related event.
- All NPV-related events that have occurred in any particular state.
- How significant each state’s contribution to the electoral vote tally has been.
- Firsts, lasts, largests and smallests.
As with many real-world data visualizations, unexpected patterns emerge. Most activity is clustered in the winter, spring and early summer, when legislative bodies are in session. The only things that happen between August and December are vetoes. This cycle will likely become much more obvious once the graphic spans a few more years.
Hawaii’s legislature overrode their governor’s second veto, and The Governator has twice robbed the plan of California’s 55 electoral votes. Neither of these facts is obvious from the current graphic. If the plan is ever repealed, the graphic would need to show that too.
As I said in Hacking the Constitution, the the National Popular Vote plan deserves a lot more attention and support, so forward this page or NPV’s website to your friends, bring it up at parties, support it with a donation, or include the graphic on your web page.
- If a geographical design were used on a visualization of the progress of this plan, it should at least be a cartogram. [↩]
- The HTML
<canvas>element might also have been a viable option, but I already knew SVG. [↩] - For a good time, try resizing the font in Safari 3. [↩]
Complexity doesn’t have to be ugly
Great diagram of Debian’s apt packaging system. It’s also a good example of the aesthetic shortcomings of automatic graph drawing tools like graphviz. It would be a good candidate for redesign by a skilled graphic designer.
What reading Tufte won’t teach you: Interface design guidelines
Edward Tufte’s books do a beautiful job of illustrating how to present huge amounts of information clearly and simply. Well presented information is critical to good interface design, but it’s not the whole story. Guidelines on how to present complex functionality clearly and simply are harder to find.
I’ve just spent two months carrying a terrible, ancient cellular phone and a mediocre non-Apple music player around the planet, and interacting almost exclusively with Windows XP terminals at internet cafes and hostels. As my frustration with these poor interfaces grew, I started a rough list of interface design guidelines. Here they are:
- The application interface should be fast and non-blocking.
- The application interface should be consistent.
- Don’t interrupt users in the middle of common, nondestructive tasks.
- Avoid notifying users of success.
- Avoid giving users information that they cannot use.
- Rare, destructive actions should be harder to complete than nondestructive ones, but always possible.
- Give users the chance to ask for forgiveness rather than forcing them to confirm.
- Deal with application failure gracefully.
- Preserve state, mode, and user input for as long as it is relevant, until users save or discard it.
- Provide multiple, complete navigation paradigms.
- Design the interface before starting to code.
- If the application violates one of these rules because its design makes implementation of a better interface too complex or too difficult, then the application needs to be refactored until it supports a better interface.
Read on for explanations and examples of good and bad design related to each one of these rules. There is a great deal of overlap between some of them, and that’s OK — they’re just guidelines. (Perhaps I, or someone else, will someday condense them into eight or nine fundamental principles of good interface design.)
The application interface should be fast and non-blocking. If it cannot be fast or non-blocking, it should appear fast and non-blocking by being immediately responsive. Many old-school web applications had disclaimers next to submit buttons saying “Click this button only once.” Submitting data over the network wasn’t fast back in the days of 56.6kbps modems, and it’s still not fast enough today. Most web applications now deal with this by disabling the submit button (good) or by changing it to a progress spinner (better) with JavaScript the first time it’s clicked. The application isn’t fast or non-blocking, but it imitates immediate responsiveness.
The application interface should be consistent. The phone I traveled with had the standard five buttons between the screen and the numeric keypad. When navigating through and controlling various applications, sometimes the left top button meant “select”, and sometimes it was the right top button. And sometimes the center menu button also meant “select,” but not always. This lack of consistency made it just plain impossible to develop a motor memory for “select” on the phone — I constantly had to think about how to select an item or confirm an action. The cross-platform widget toolkit wxWidgets ensures that dialog boxes it creates match the standard order of OK, Cancel, Yes, and No buttons on whichever platform the application is running on.
Don’t interrupt users in the middle of common, nondestructive tasks.The basic, core functionality of the application should be free from confirmations, interruptions, dialog boxes, configuration questions, multiple steps, wizards, and other garbage. Get out of the way and let users do what they need to do. Windows XP’s information bubbles that pop up out of the system tray, on top of other windows, are particularly egregious violators of this rule. Dialog boxes in Windows and on Linux also break this rule, as an error in a background application can interrupt the user mid-task in another application. Mac OS X’s design that puts dialogs into “sheets” attached to the parent window ensures that a dialog box never interrupts a task in a different application. If one application, or the operating system, violates this rule, it can interrupt users while they are using a different application and therefore affect the usability of the entire system. Websites for DTF publications like the New Yorker violate this rule when they split their articles up into multiple pages — maybe this is motivated by some weird desire to mimic turning of a page, but more likely it’s to track readers and increase ad views. Don’t do it. Reload ads and track readers with JavaScript if necessary.
Avoid notifying users of success. In general, an application should allow users to assume that everything is successful unless they hear otherwise. If a delayed or background process or command has completed, and notification of its success will help users to continue their work, then that notification must be radically different than failure notification. Windows’ information bubbles are a serious violator of this rule too. When plugging a new device into a Windows machine, it will often emit three or four info bubbles, with a sequence of messages like this: “New hardware connected,” “CanonSony XJ-4000 PowerCyberShot found,” and then “Your new hardware is ready to use.” OS X gets this right; plug in a camera and iPhoto launches, ready to import the photos. It doesn’t say, three times, that a camera has been connected. iPhoto launching is an implicit indication of a successful connection with the camera. Lots of web applications are doing the right thing by putting success notifications in the page, in little unobtrusive boxes, and putting error messages in red, in a different place on the page. Using dialog boxes for errors, confirmations, and informative messages, as most applications did for years, just trained users to always click “OK.”
Avoid giving users information that they cannot use. Users still must read, think about, and decide that the information is useless. If the information is useless to begin with, why risk confusing them? Why slow them down to read it? Every time I plug my USB CF card reader into a Windows machine, it gives me an info bubble that says “This device could function faster if it were plugged into a USB 2.0 port.” And it says this even if the computer has no USB 2.0 ports at all. What are users supposed to do with this information? Run out and buy a USB 2.0 card? Or a new computer? How many non-technical users actually know what “USB 2.0” means, and can correctly decide to discard this information? The information bubbles in the previous example fail here too. Users don’t need to know that new hardware has been connected, or what model of camera they just connected, because, he or she is the person who plugged the camera in. When people are working together on a project, they don’t call each other every thirty seconds to tell the rest of the team that they successfully typed another word into the report or entered another figure into the spreadsheet.
Rare, destructive actions should be harder to complete than nondestructive ones, but always possible. Closing a file without saving or emptying the trash are examples of destructive actions. If most of the actions in an application are destructive, consider building an action history with an “undo” command or a back button into it. Make as many actions as possible nondestructive. And don’t just skip implementing destructive actions — building a web application without a “delete account” command is criminal. For a long time, one of the t-shirt sites that I’d used didn’t have a way to delete a shirt — just a blurb saying to email customer support with the shirt ID. In the rare case where users do want to perform a destructive action, they are positive that they want to perform it. If it’s missing, the application seems ten times more unfinished and underpowered.
Give the user the chance to ask for forgiveness rather than forcing them to confirm a (destructive) action. Gmail and other web applications are pioneering this one. Rather than asking something like “Are you sure you want to delete this conversation?” they provide a success notification “The conversation has been deleted” with an “undo” button next to it. The insight here is that, although the application must provide a way to immediately abort a destructive action like this, 99% of the time, users actually intended to perform the destructive action. That should be the easy, one-click case, and aborting the destructive action should be the rarer, two-click case.
If the application pesters users with a confirmation dialog for destructive actions, users memorize a multi-step destructive command: click delete, then click OK — and when they accidentally delete the wrong thing, they miss the chance to abort. Many, many applications are guilty of this.
Deal with application failure gracefully. Don’t lock users out or lose state in the event of an application failure. Users witnessing an application failure are in the most stressful and worried mental state they will ever be in while using the application. The interface for alerting users about an application failure and recovering from it should be the smoothest, simplest, most comforting part of the interface.
Preserve state, mode, and user input for as long as it is relevant, until the user saves or discards it. Never make users answer the same question or enter the same information twice. Was there an error when saving? Show the form again with everything the user entered. Did the user switch the telephone keypad to Title Case? Stay on title case when the word isn’t in the predictive text dictionary and the user has to spell it. Take advantage of the fact that computers are better at remembering than anything else.
Provide multiple, complete navigation paradigms. Keyboard and mouse control, back and forward buttons, search and choose, scroll and jump, broad and deep, fast and slow. Digital bedside clocks and watches are particularly bad violators of this. Often they provide, to set the time, just “up” and “down” buttons, or “fast up” and “slow up” buttons. With these two-button interfaces, users must hold down one of the buttons and watch the time change. While performing boring, slow tasks like this it’s easy for humans (your users) to get distracted, miss the target time, and have to go all the way around again, or back in the other direction, slowly. A speed sensitive knob, like on analog watches, or even just ten numeric buttons, would be a much superior navigation interface.
The iPhone lets the user scroll slowly through their address book, or click on a letter and jump ahead in the alphabet. The speed of the scroll when dropping an item into a long list in a scrolled window should depend on how far from the edge the item is being dropped. Would an e-commerce site succeed with just browse-by-category and no search? The phone I carried had one button to cycle to the next word in the group of words offered by the predictive text system, but no way to go back to the previous word. Press next too many times? Sorry, you have to cycle through all nine words all over again.
Design the interface before starting to code. Even just a sketch will help — what commands and what functionality is going to be accessible? When and where? What will need extra heuristics? What will need custom widgets? What are the trouble spots? And don’t just copy what some other application has done. Even great interfaces have problems — copy what’s good and improve what isn’t. Didn’t design the interface before starting to code? Stop now and design it.
If the application violates one of these rules because its design makes implementation of a better interface too complex or too difficult, then the application needs to be refactored until it supports a better interface. This one is sometimes the hardest to swallow — how could an application with a mathematically perfect algorithm and beautifully coded implementation of it need to be re-engineered? If the excuse for not implementing a powerful new feature is a back-end that can’t support it, then that back-end, no matter how awesome it is, is not good enough, and rewriting is the only option. A better UI is one of the most powerful new features that can be added to an application, so if it requires a redesign and a rewrite, so be it.