Unless you’ve only ever worked with technical people, you’ve run into the old “is it a bug or is it a feature” argument. Generally, a business person reports something as a bug because it’s not working properly, but the reaction from technical people is that that particular feature just isn’t built yet or that specific detail was not in the original specification. This can be a source of great friction because it usually involves technical people saying the product will take longer than expected to finish. Less often, business will report a problem as a new feature, but the problem is already-built code that is just not functioning properly. This is less contentious because it usually means it’s less work to fix than business originally thought.
Is there a way to eliminate this debate?
Organizations handle this problem in different ways. Some organizations try to specify in excruciating detail, and while there is a benefit to getting complete specs, you are never going to catch all of the edge and corner cases. Speccing can reduce these kinds of disagreements, but you’ll still always have the “is it a bug or is it a feature” debates coming up.
Larger organizations have customer support, quality assurance, and product planning processes and infrastructure in place, whereby an issue originally reported as a bug is converted into a feature and estimated properly by the time an developer starts implementation.
But if you’re a small start-up, you probably don’t have time to spec every detail of your product, and you probably don’t have the resources for customer support and quality assurance to translate business and customer-speak into technical terms. In a start-up you often have the business visionary and the technical people interacting directly, and that’s when the all-too-familiar “bugs or features” arguments can be the most severe.
My experience in start-ups means that I’ve almost always been in this situation. And struggling to come up with a good definition for, or boundary between, certain categories, quite often is an indication that the categories or boundaries that you’re trying to define are flawed and not terribly useful concepts. For example, ask a linguist to come up with a language-independent definition of what is and isn’t a word, or a hard and fast rule defining the boundary between a dialect and a language, and most will tell you that those fuzzy real-world concepts don’t really have any rigorous scientific utility in linguistics.
So I’ve been wondering whether the whole bug / feature boundary is problematic because it isn’t rigorously definable. If that were the case, then we would be able to come up with different concepts that are easily definable. And we can.
This is best explained by pictures (and I’ve been a little inspired by Matt Might’s illustrated guide to a PhD.)
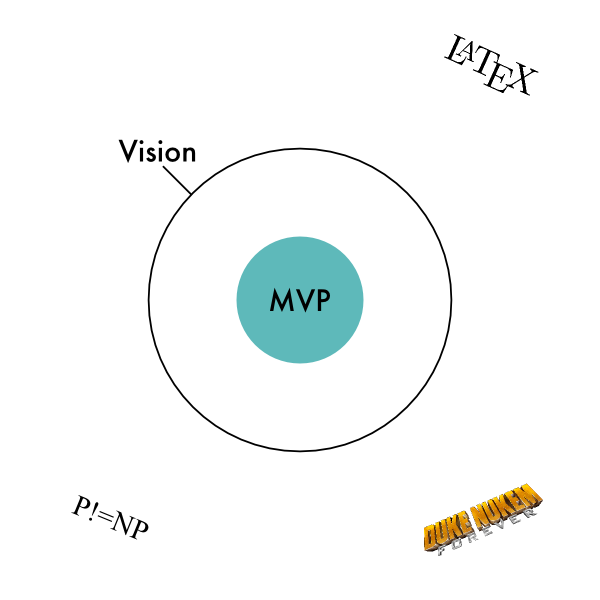
Imagine the space below is the space of all possible software. There are two zones you should be concerned with. The first is your vision—software you someday want to build, and inside that is your MVP—the software you have already built. Outside of your vision is software that you don’t want to build.
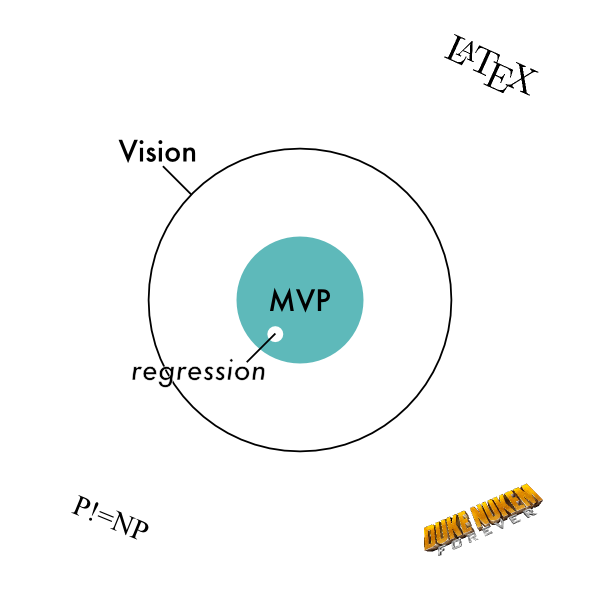
The first concept I want to introduce is that of a regression. A regression is something that used to work but doesn’t work anymore. Diagrammatically, a regression is a hole that appears in the middle of the software you’ve already built. If there’s disagreement whether or not something is actually a regression, it should be easy to verify by checking an earlier version of the software.
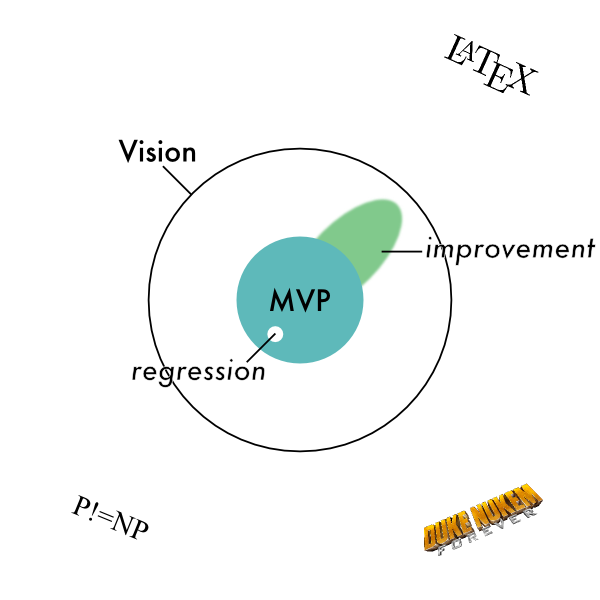
The next concept is an improvement, when you start to expand the zone of functionality of the software.
If you have specified this improvement, then that specification is the border of the zone that you’re going to be expanding into.
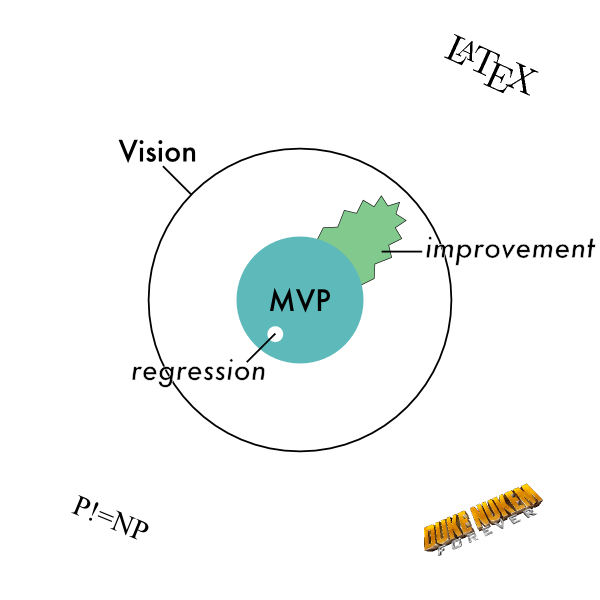
The more detailed the specification, the more detailed this boundary is.
These two concepts, regression and improvement, roughly correspond to things that everyone will agree are bugs or features.
The third concept is the flaw. A flaw lies on the boundary of an improvement—one that’s being made or has already been made. It doesn’t stand on its own as an independent improvement, so it’s the kind of thing that a business person would have a hard time thinking of as a feature. But it’s also not something that any developer has ever spent any time implementing, so it’s hard for a technical person to think of it as a bug.
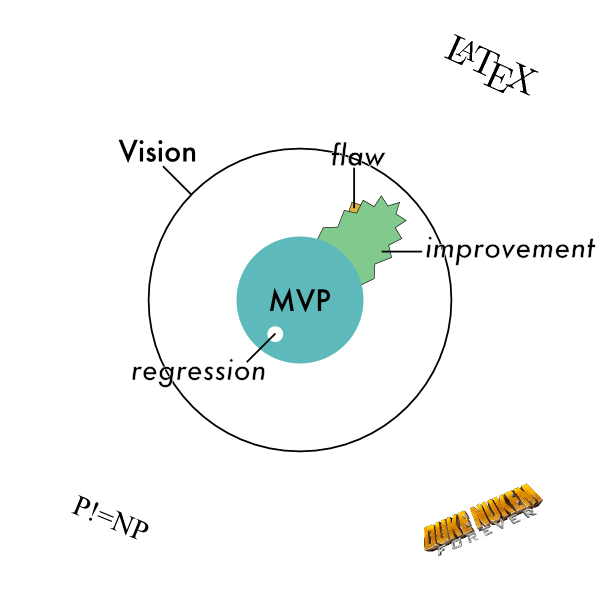
Sometimes flaws can even appear long after an improvement has been considered completed by everyone.
So, there’s really no reason to keep debating whether things are bugs or features, when there are three rigorously-definable concepts that could easily replace them:
- regression: something that used to work but does not not any longer
- improvement: a self-contained expansion of the programs capabilities
- flaw: something that does not work (correctly) because it was not included while implementing an improvement
I started using these concepts with my product owner a couple of months ago and it has vastly improved our discussions and planning.