There is a common belief that git merge --rebase is somehow preferable to normal merging. The general assertion seems to be that a linear history is somehow “cleaner”, “easier to understand“, and that normal merging introduces “extra commits” and “merge bubbles“, the latter presumably being only slightly less objectionable than economic bubbles. Some organizations even go so far as to mandate always merging with --rebase. But ask someone to give a real, technical justification—just one—for this belief, and they mumble some aesthetic vapidities and then start talking about the weather.
Let’s put aside for a moment the ridiculous assertion that a directed acyclic graph is somehow more difficult for programmers—programmers!—to understand than a linear history. I want to show you how normal merging is in fact preferable to using --rebase all the time.
Assume you have a good test suite and a policy of making sure the application runs, and the tests pass, on each commit. If your team doesn’t do this, stop reading random blog posts and implement it. This allows everyone on the team to make heavy use of git bisect—if someone finds a regression not covered by the tests, it’s easy to bisect the history to find the change that introduced that regression. And the most maddeningly nondeterministic bug usually becomes obvious when you have the single diff that introduced it in front of you. If you don’t know git bisect, stop reading random blog posts on the internet and learn it.
If you have a branch that’s in progress, you can of course just create a series of checkpoint commits, and when you’re done, rearrange them with git rebase -i ANCESTOR. But at the end, your history should be a series of self-contained commits, each one with a single purpose. Usually, this takes the form of:
- a few commits fixing bugs found while working on the feature
- a commit or two refactoring some existing parts of the application
- a few commits introducing the new feature(s) you were working on
This is relatively safe, especially when you are careful to fix the relevant tests along with each commit.
The problem arises when you merge upstream branches into your current branch with git merge upstream --rebase. The basic situation is this: You do some work in a branch, commit it, and make sure the tests are all running. Then someone else makes a breaking change in the upstream branch, which breaks code that you have introduced in your branch. Before you merge, you have something that looks like this:
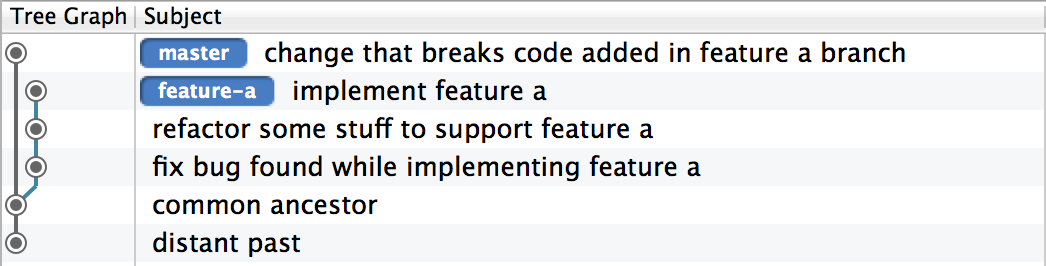
If you merge upstream in normally, you’ll notice the breaking change when you run the tests, and fix it in the merge commit, or the next commit. You’ll end up with at most one, and possibly zero, commits where the tests fail and the application won’t run. If you fix your application in your merge commit, then in no sense is your merge commit extraneous. Your history looks like this:

However, if you git merge upstream --rebase, the upstream commit that broke your work ends up before all the commits on your branch. You’ll again notice the breaking change immediately, but since there’s no merge commit, you have no chance of ensuring that the application runs and the tests pass on every commit. In this example, there are now three commits where the application does not run and the tests do not pass:
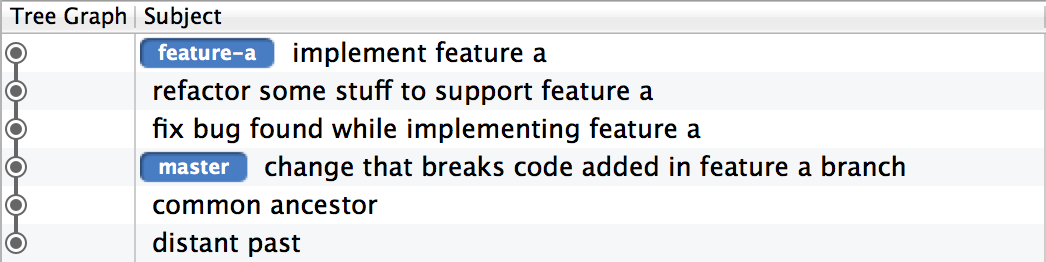
You now have two options: fix the code in a new commit against HEAD, or go back and edit all your previous commits and fix each one to work with the new changes you just inserted in the history. The second option is a lot of work with git rebase -i; nobody wants to do that. It’s much easier to just fix the code in a new commit, and then continue working on your branch:

But now you still have a history with a series of commits where the application doesn’t run and the tests don’t pass. In fact, nobody has ever even run the code in those commits, so who knows what could be going in in there.
Would you rather have a history that satisfies some sort of vague and unjustified need for simplicity or cleanliness, or a history with a guarantee that git bisect will always work?